Columbia University’s Nima Mesgarani is developing a computer-generated speech method for those who are unable to talk.
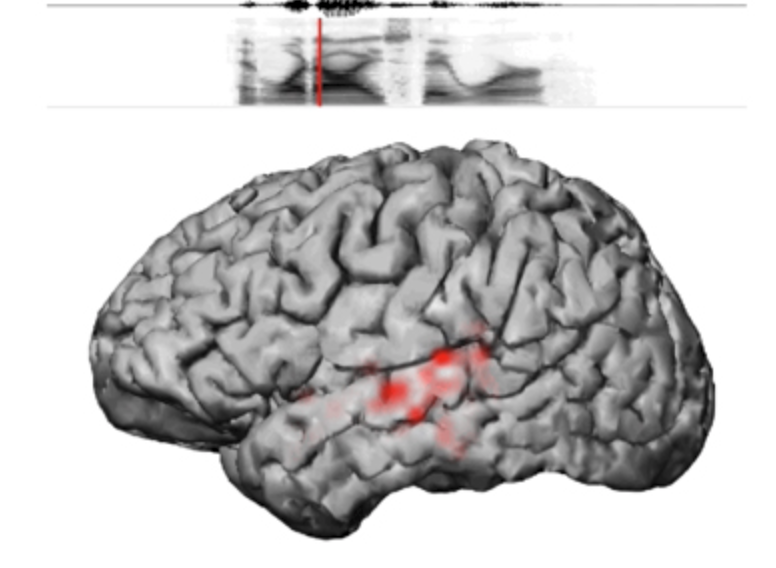
How brain signals translate to speech sounds varies from person to person, therefore computer models must be trained individually. The models are most successful when used during open skull surgeries, to remove brain tumors or when electrodes are implanted to pinpoint the origin of seizures before surgery.
Data is fed into neural networks, which process patterns by passing information through layers of computational nodes. The networks learn by adjusting connections between nodes. In the study, networks were exposed to recordings of speech that a person produced or heard and data on simultaneous brain activity.
Mesgarani’s team used data from five epilepsy patients. The network analyzed recordings from the auditory cortex as participants heard recordings of stories and people naming digits from zero to nine. The computer then reconstructed spoken numbers from neural data alone.
Click to view Science magazine’s sound file of the computer reconstruction of brain activity.
Join ApplySci at the 10th Wearable Tech + Digital Health + Neurotech Silicon Valley conference on February 21-22 at Stanford University — Featuring: Zhenan Bao – Christof Koch – Vinod Khosla – Walter Greenleaf – Nathan Intrator – John Mattison – David Eagleman – Unity Stoakes – Shahin Farshchi – Emmanuel Mignot – Michael Snyder – Joe Wang – Josh Duyan – Aviad Hai – Anne Andrews – Tan Le – Anima Anandkumar – Pierrick Arnal – Shea Balish – Kareem Ayyad – Mehran Talebinejad – Liam Kaufman – Scott Barclay